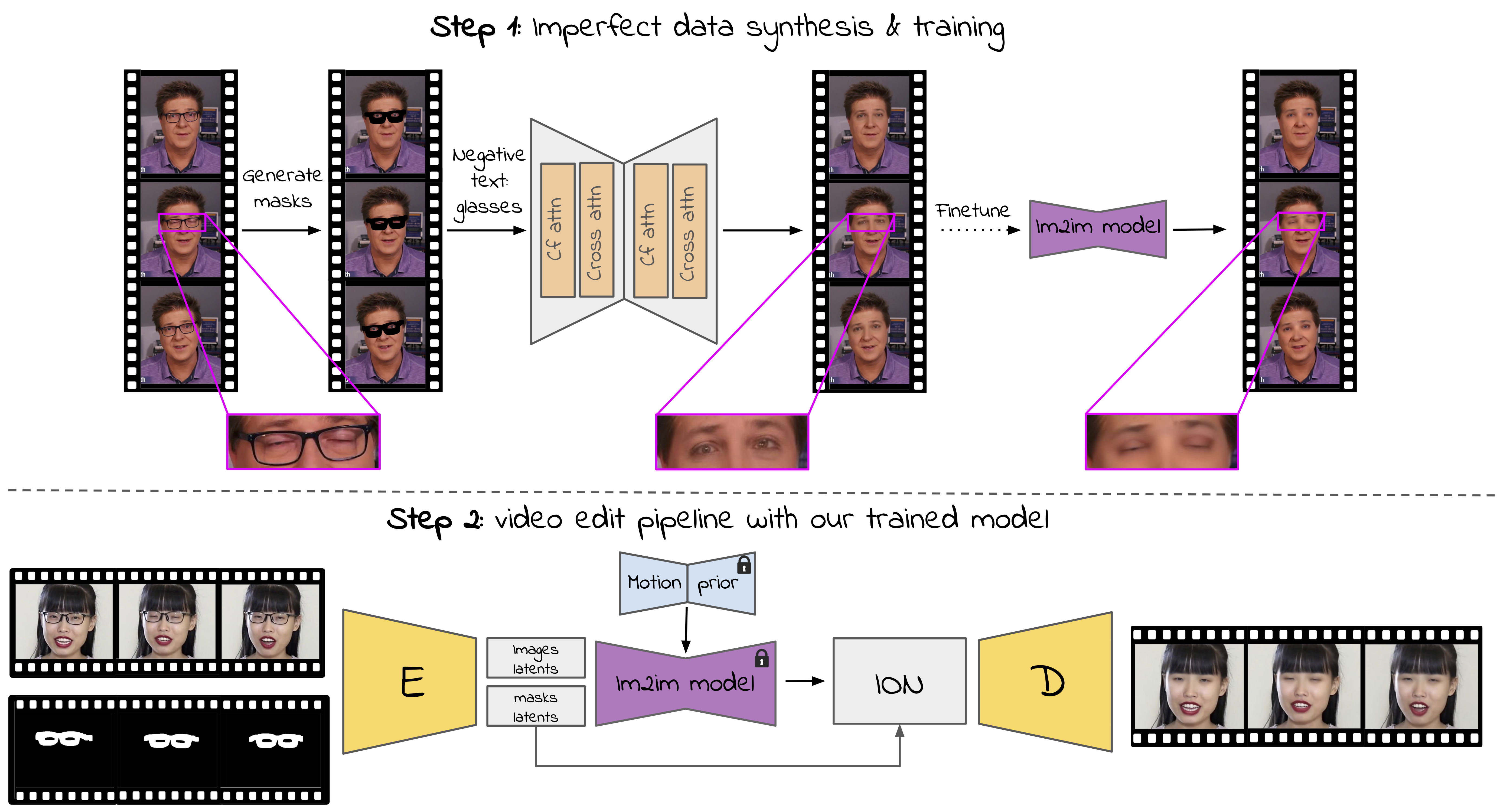
Method overview:
Step 1: we create an imperfect synthetic paired dataset by generating glasses masks for each video frame and inpainting it. We inpaint each frame using an adjusted version ControlNet inpaint. We replace the self-attention layers with cross-frame attention (cf attn) and use blending between the generated latent images and the noised masked original latent images at each diffusion step. The generated data in the first step is imperfect; e.g. in the middle frame, the person blinks, however its generated pair has open eyes. Nevertheless, the data is good enough for finetuning an image-to-image diffusion model and achieving satisfactory results, due to the strong prior of the model.
Step 2: Given our trained model for the task of removing glasses from images, we incorporate it with a motion prior module to generate temporally consistent videos without glasses from previously unseen videos. To obtain the original frame colors, at each diffusion step we blend the generated frames with the noised original masked latent images, and before decoding, we apply an Inside-Out Normalization (ION), to better align the statistics within the masked area and the area outside of the mask.